





![]() The packing of data is good practice for many reasons, including disk space and efficient RAM or cache access. If we know the meaning of data we can often narrow down the range and precision, making informed decisions as to the amount of bytes we need. I was inspired once by this article and here’s my take on the topic. We’ll explore common ways of packing certain kinds of data common in videogames, their possible implementation and rationale; worthy of note is that this is not an article about compression. I’ll be using HLSL syntax but this will look very familiar to C++ and can be ported easily to any other language.
The packing of data is good practice for many reasons, including disk space and efficient RAM or cache access. If we know the meaning of data we can often narrow down the range and precision, making informed decisions as to the amount of bytes we need. I was inspired once by this article and here’s my take on the topic. We’ll explore common ways of packing certain kinds of data common in videogames, their possible implementation and rationale; worthy of note is that this is not an article about compression. I’ll be using HLSL syntax but this will look very familiar to C++ and can be ported easily to any other language.
Normalized Data
This is the simplest type of data to pack so we’ll start here. Normalized data ranges from 0 to 1. You can easily normalize data by shifting and dividing by its maximum value. This mostly applies to colors or bounded values (think a shadow or transparency term) and sometimes normalized vectors, although there are better methods as we’ll see later. The D3D12 formats for this kind of data are the _UNORM class, such as R8G8B8A8_UNORM or R16G16_UNORM. The code examples below show how to encode a typical color with alpha into 8 and 16 bits, they are common cases but you can make as many variations as needed depending on the bitrate and the data you want to store.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | uint PackFloat4ToRGBA8Unorm(float4 value) { uint4 uvalue = uint4(value * 255.0 + 0.5); return (uvalue.a << 24) | (uvalue.b << 16) | (uvalue.g << 8) | uvalue.r; } float4 UnpackRGBA8UnormToFloat4(uint packed) { uint ri = packed & 0xff; uint gi = (packed >> 8) & 0xff; uint bi = (packed >> 16) & 0xff; uint ai = packed >> 24; return float4(ri, gi, bi, ai) / 255.0; } uint PackFloat2ToRG16Unorm(float2 value) { uint2 uvalue = uint2(value * 65535.0 + 0.5); return (uvalue.g << 16) | uvalue.r; } float2 UnpackRG16UnormToFloat2(uint packed) { uint ri = packed & 0xffff; uint gi = packed >> 16; return float2(ri, gi) / 65535.0; } |
Note how we add 0.5 to the result after multiplying by 255. This operation followed by casting is equivalent to rounding but avoids the round instruction since the add gets factored into the multiply-add. Some of these operations are so common that many closed platforms have intrinsics or special instructions to encode and decode bits. Recently, HLSL added some special packing instructions to Shader Model 6.6 so we can also write the RGBA8 packing as follows.
1 2 3 4 5 6 7 8 9 10 | uint PackFloat4ToRGBA8Unorm(float4 value) { uint4 ivalue = uint4(value * 255.0 + 0.5); return pack_u8(uvalue); } float4 UnpackRGBA8UnormToFloat4(uint packed) { return float4(unpack_u8u32(packed)) / 255.0; } |
We’ll stop here for a minute to analyze the RDNA bytecode generated from these instructions. I have grouped them to make logical sense as the compiler is free to reorder these. These tests were performed on the Radeon Graphics Analyzer using the 1103 RDNA3 ASIC in offline mode. We need to be careful as older RGA versions produce worse than the baseline, whereas the latest one I used here shows an improvement. As always, measure and make sure! The command line I used, should you wish to replicate the results, is .\rga.exe -s dx12 -c gfx1103 –offline –cs example.hlsl –cs-entry CSMain –cs-model cs_6_6 –dxc-opt –isa example_hlsl_v1.txt
|
| ||||
|
|
As you can see the compiler is able to improve our hand-written logic and squeeze a couple extra instructions for our packing using v_perm_b32, an instruction that swizzles values into a single one. We don’t have the high-level instructions to perform the same operations manually which is unfortunate. There are other normalized formats commonly used in videogames that don’t have the same bit width for all components, for example R5G6B5, R5G5B5A1 or R10G10B10A2 formats. We can see how to encode and decode one of them below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | uint PackFloat4ToRGB10A2Unorm(float4 value) { uint3 rgbi = uint3(value.rgb * 1023.0 + 0.5); uint ai = uint(value.a * 3.0 + 0.5); return (ai << 30) | (rgbi.b << 20) | (rgbi.g << 10) | rgbi.r; } float4 UnpackRGB10A2UnormToFloat4(uint packed) { uint ri = packed & 0x3ff; uint gi = (packed >> 10) & 0x3ff; uint bi = (packed >> 20) & 0x3ff; uint ai = packed >> 30; return float4(float3(ri, gi, bi) / 1023.0, ai / 3.0); } |
Signed Normalized Data
Encoding positive normalized data works well with the method above. When the normalized data can be negative as well, unexpected things can happen if we’re not careful. For example, let’s try to encode a normal vector pointing upwards (0, 1, 0) using what we know so far.
1 2 3 4 5 6 7 8 | // Remap normal from -1, 1 to 0, 1 float3 normal = float3(0.0, 1.0, 0.0) * 0.5 + 0.5; // Now contains (128, 255, 128) uint3 encodedNormal = uint3(normal * 255.0 + 0.5); // Now contains (0.003921, 1.0, 0.003921) float3 decodedNormal = float3(encodedNormal / 255.0 * 2.0 - 1.0); |
Notice how zero cannot be represented exactly and now the decoded vector is tilted slightly sideways (always biased towards +xz in a positive y coordinate system). If you’re using something like this to encode normals for vertex data or in textures, you’ll see e.g. mirror reflections looking slightly tilted instead of properly aligned. We can see why visually:
| 0 | 1 | … | 126 | 127 | 128 | 129 | … | 254 | 255 |
| -1.0 | -0.992156 | … | -0.011764 | -0.003921 | 0.003921 | 0.011764 | … | 0.992156 | 1.0 |
Signed normalized data formats, such as the D3D12 formats in the _SNORM class, have a couple of special rules that help us fix the above problem. Reading the DirectX documentation in this regard, we’ll see this small snippet:
The minimum value means -1.0f (e.g. the 5-bit value 10000 maps to -1.0f). In addition, the second-minimum number maps to -1.0f (e.g. the 5-bit value 10001 maps to -1.0f). There are thus two integer representations for -1.0f. There is a single representation for 0.0f, and a single representation for 1.0f
The whole point of the above paragraph is to make sure we are able to accurately represent 0, even if we need to lose one of the values and repeat the value -1.
| -128 | -127 | -126 | … | -2 | -1 | 0 | 1 | 2 | … | 126 | 127 |
| -1.0 | -1.0 | -0.992125 | … | -0.01574 | -0.00787 | 0.0 | 0.00787 | 0.01574 | … | 0.992125 | 1.0 |
We now present the code to pack and unpack. Notice how we use round to make sure we add 0.5 for positive numbers and subtract 0.5 in the case of negative numbers. Worthy of note too is that we need to operate with ints instead of uints to get sign extension. Simply masking the bits and casting to int won’t preserve the sign bit, which is the reason we shift left and shift back right. It’s the same thing that happens in C++ (conceptually) when casting a char to int. Fortunately for us the compiler knows exactly what we want to do and removes the shifts using the bitfield extract instruction (v_bfe_i32) which we’ll see later.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | // Assume input is in the -1, 1 range, for both packing and unpacking. Clamp accordingly if the input is unknown uint PackFloat4ToRGBA8Snorm(float4 value) { int4 ivalue = int4(round(value * 127.0)); return (uint)((ivalue.a << 24) | (ivalue.b << 16) | (ivalue.g << 8) | ivalue.r); } float4 UnpackRGBA8SnormToFloat4(uint packed) { int ri = (int)(packed << 24) >> 24; int gi = (int)(packed << 16) >> 24; int bi = (int)(packed << 8) >> 24; int ai = (int)(packed << 0) >> 24; return float4(ri, gi, bi, ai) / 127.0; } |
An alternative version using the pack_s8 HLSL 6.6 intrinsic provides us with some gains too, code below using RGA as well.
|
| ||||
|
|
Bitfields
For more arbitrary packing we can resort to bitfields. This usage however comes with the caveat that shader compilers are only just catching up. DXC recently started supporting them, and they work in some closed platforms, but they don’t work in any flavor of GLSL I know of. One really good use case I can think of for this is flags. The standard way of doing flags by hand looks more or less like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | struct Data { uint flags; }; static const uint Feature1 = 0x1; static const uint Feature2 = 0x2; static const uint TypeMask = 0xC; Data data; if(data.flags & Flag1) { // Do something } uint type = data.flags & TypeMask; |
However, keeping the application (the code that packs the data) and shader (the code that consumes the data) in sync can sometimes be tricky and error-prone. Using bitfields makes it easy to make changes without having to deal with code changes elsewhere that you might miss. The bitfield way of doing the above would look as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 | struct Data { uint feature1 : 1; uint feature2 : 1; uint type : 2; }; Data data; if(data.flag1) { // Do something } uint type = data.type; |
We can test this in Godbolt and visualize the corresponding RDNA assembly (HLSL support was mainly added by Jeremy Ong, go show his blog some love)
|
| ||||
|
|
Our new code on the right is slightly more optimal than the code on the left, even though they are functionally equivalent. The bitfield extract instruction s_bfe_i32 is able to create a mask while checking the bit, allowing it to use it directly in the conditional select without needing the compare instruction. Of course, this is up to the compiler and you might find that some bit patterns fare better than others in this regard.
Bit Extraction and Insertion
We can now introduce the concept of extracting and inserting an arbitary number of bits at arbitrary offsets. These kinds of functions prove to be very useful when bitpacking custom data for a particular algorithm and making sure that both packing and unpacking are consistent. These are so useful that there are low level instructions to do this such as RDNA’s bfe (bitfield extract) and bfi (bitfield insert). GLSL provides high-level bitfieldExtract and bitfieldInsert for this purpose and some proprietary platforms provide intrinsics too. With HLSL however, we are incomprehensibly out of luck and we’ll have to create a function that tries to hint the compiler to produce the same code. The RDNA manual tells us exactly what the instruction does and we copy the pattern. Make sure both your offset and bits are clamped to 31 to avoid overflowing, and make sure you mark all 1 as 1U, otherwise it will not produce the desired bfe. Unfortunately for bfi I have not been able to reliably emit the instruction, even using the GLSL bitfieldInsert. Be careful with the definition of some of these functions; I have found that the one in NVIDIA’s old Cg repository is slightly different because it doesn’t mask the insertMask.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | // These are emulations of the low-level RDNA instruction // If you have access to an intrinsic you can replace it uint bfe_u32(uint value, uint offset, uint bits) { uint mask = (1U << bits) - 1U; uint shiftValue = value >> offset; return shiftValue & mask; } uint bfi_b32(uint value, uint preserveMask, uint insertMask) { return (value & preserveMask) | (~value & insertMask); } // Extract bits numbers of bits at an offset from value uint BitfieldExtract(uint value, uint offset, uint bits) { return bfe_u32(value, offset, bits); } // Insert low bitCount bits of insert at an offset in base uint BitfieldInsert(uint value, uint insert, uint offset, uint bits) { uint preserveMask = ~(~(0xffffffffU << bits) << offset); uint insertMask = insert << offset; return bfi_b32(value, preserveMask, insertMask); } |
As an exercise we could rewrite one of the above packing/unpacking functions with these new functions. Using our emulated bfi_b32 or bfe_b32 can be slower than the explicit way of writing it, especially for common formats, so make sure to measure instruction count and use the intrinsics available to you in different platforms.
1 2 3 4 5 6 7 8 9 10 | uint PackFloat4ToRGB10A2Unorm(float4 value) { uint3 rgbi = uint3(value.rgb * 1023.0 + 0.5); uint ai = uint(value.a * 3.0 + 0.5); uint result = rgbi.x; result = BitfieldInsert(result, rgbi.y, 20, 10); result = BitfieldInsert(result, rgbi.z, 30, 10); result = BitfieldInsert(result, ai, 32, 2); return result; } |
1 2 3 4 5 6 7 8 | uint UnpackRGB10A2UnormToFloat4(uint packed) { uint ri = BitfieldExtract(packed, 0, 10); uint gi = BitfieldExtract(packed, 10, 10); uint bi = BitfieldExtract(packed, 20, 10); uint ai = BitfieldExtract(packed, 30, 2); return float4(ri / 1023.0f, gi / 1023.0f, bi / 1023.0f, ai / 3.0f); } |
Floating Point Data
Data with a large range and a non-uniform distribution of values is what floating point is for. If you want to fully understand floating point it doesn’t get any better than Bruce Dawson’s articles on the topic, a good introduction here and a lot more details here., and a more recent article by Adam Sawicki is well worth the read. Floating point can be tricky but we don’t think about it much in general as hardware support is ubiquitous and transparent. The question here is how to pack or compress floating point data, and this is where small float formats come into play, and more recently minifloats. There’s a really good article that explains a small floating point format for colors, downsides and comparisons with 8-bit uniform color precision. You can read up more on the IEEE format definitions for 64-bit double, 32-bit float, 16-bit half and minifloats as well. Another excellent article on 8-bit floats can be found here. Here we’ll do a practical 101 course to understand floating point and then learn how to deal with the smaller formats. Understanding how floats work will help us follow the next section. If after this you want to read even more about floating point, this is also a good resource on the topic. Take a look at the following table:
| Total Bits | Sign Bit | Exponent Bits | Mantissa Bits | Exponent Bias | Range | Smallest |
| 64 | Yes | 11 | 52 | 1023 | ±1.798e+308 | 2.225e-308 |
| 32 | Yes | 8 | 23 | 127 | ±3.403e+38 | 1.175e-38 |
| 16 | Yes | 5 | 10 | 15 | ±65504 | 6.104e-5 |
| 11 | No | 5 | 6 | 15 | +65024 | 6.104e-5 |
| 10 | No | 5 | 5 | 15 | +64512 | 6.104e-5 |
| 8 | Yes | 4 | 3 | 7 | ±240 | 1.563e-2 |
| 4 | Yes | 2 | 1 | 3 | ±12 | 2.5e-1 |
There are 3 main concepts we care about when dealing with floating point: the sign, the exponent and the mantissa. An alternative formulation of this can be found here, but I’ll stick with the classics. The sign allows us to have negative numbers, and generally speaking the exponent is what allows us to have numbers ranging from the really small to the really big, while the mantissa gives us decimal precision. There are other considerations that affect a format such as whether it supports nans, infinities and denormals handling. We’ll touch on these topics at the end to avoid complicating things too early.
A decimal value 1234.5678 can be expressed in scientific notation as follows:
{\Large1.2345678 \cdot 10^{3} =1234.5678}
One can think of floating point as a scientific notation in binary, where we replace the base 10 with base 2 and we encode the mantissa in binary. We also assume an implicit bit m0 that is usually 1 except for the special case of denormals. The exponent is biased (shifted), as half of the range is dedicated to negative exponent and the other half to positive exponents. To clarify, the exponent of 0 is represented by 127 in the case of 32-bit floats, 15 in the case of halfs, etc.
{\Large (-1)^{\textcolor{30e6f0}{\textbf{s}}} · \textcolor{f58787}{m_0.m_1m_2m_3...m_{23}} \cdot 2^{\textcolor{6dea80}{\textbf{e - bias}}}}
To convert the number to binary we can use a general algorithm for base conversion: in our case we subdivide the integer part by 2 and successively multiply the fractional part by 2 taking note of the remainder to set the bits appropriately. We’re trying to extract the positional value for each of the powers of 2 this number covers. At risk of being too verbose for those who already know it, I’ll just lay it out here step by step.
Integer Part (1234)
| Step | Bit | Positional Multiplier |
| 1234 / 2 = 617 | 0 | 20 |
| 617 / 2 = 308.5 | 1 | 21 |
| 308 / 2 = 154 | 0 | 22 |
| 154 / 2 = 77 | 0 | 23 |
| 77 / 2 = 38.5 | 1 | 24 |
| 38 / 2 = 19 | 0 | 25 |
| 19 / 2 = 9.5 | 1 | 26 |
| 9 / 2 = 4.5 | 1 | 27 |
| 4 / 2 = 2 | 0 | 28 |
| 2 / 2 = 1 | 0 | 29 |
| 1 / 2 = 0.5 | 1 | 210 |
Fractional Part (0.5678)
| Step | Bit | Positional Multiplier |
| 0.5678 * 2 = 1.1356 | 1 | 2-1 |
| 0.1356 * 2 = 0.2712 | 0 | 2-2 |
| 0.2712 * 2 = 0.5424 | 0 | 2-3 |
| 0.5424 * 2 = 1.0848 | 1 | 2-4 |
| 0.0848 * 2 = 0.1696 | 0 | 2-5 |
| 0.1696 * 2 = 0.3392 | 0 | 2-6 |
| 0.3392 * 2 = 0.6784 | 0 | 2-7 |
| 0.6784 * 2 = 1.3568 | 1 | 2-8 |
| 0.3568 * 2 = 0.7136 | 0 | 2-9 |
| 0.7136 * 2 = 1.4272 | 1 | 2-10 |
| 0.4272 * 2 = 0.8544 | 0 | 2-11 |
| 0.8544 * 2 = 1.7088 | 1 | 2-12 |
| 0.7088 * 2 = 1.4176 | 1 | 2-13 |
We need to stop here as we have run out of digits in the mantissa. This means that often, numbers that are perfectly represented in decimal cannot be exactly represented in floating point. Now we have a number 10011010010.1001000101011 that has 24 digits (the amount we can fit in the mantissa – 1). It’s now time to find the exponent; regular floating point numbers have an implicit 1 we don’t store that appears before the dot. Therefore, we need move the decimal point 10 positions to the left, meaning our exponent is a 10 in decimal. Accounting for the bias of 127 for 32-bit floats, 127 + 10 = 137, which in binary is 10001001. Our final floating point value looks as follows:
{\Large\textcolor{30e6f0}{\textbf{+}}\textcolor{f58787}{\textbf{1.0011010010}}\textcolor{f58787}{1001000101011} \cdot 2^{\textcolor{6dea80}{\textbf{10001001}}}}
The final floating point value in memory would look like this:
| 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
As we said earlier, 1234.5678 cannot be represented exactly in 32-bit floating point, so the value we store is 1234.5677490234375 which is close but not exact. If you want to verify this result you can add up the non-zero positional multipliers (i.e. 210 + 27 + 26 + … + 2-1 + 2-4 … + 2-13), or experiment with this neat calculator. This is a source of error and a constant tradeoff when working with limited precision representations, but these formats are generally so good that more often than not we don’t think of how they work. Now that we understand how floating point works, we can see that coming up with different formats based on these same principles is relatively straightforward. The tradeoffs we’ll be making is in the bits assigned to the exponent (range) and the mantissa (decimal precision).
Half Format
16-bit floats or halfs, as we’ll call them from now on, are a very popular format for videogames. Their history is storied; back in Generation 7 consoles and before, HDR texture formats were complicated. RGBA16F and similar were available but non-blendable, you could use uniform precision RGB10A2 with a limited range, and there were custom things like the 7e3 Xbox 360 format; 32-bit float was totally out of the question. In terms of shaders, halfs were available as a type you could use for math in some consoles but during the D3D10 era they disappeared on PC, and were forgotten until Generation 9 brought them back. On mobile the situation is a bit different; they’ve always had these smaller types as they can make a big difference to performance. If you want to use these in shaders and want to know the practicalities and compilation flags, this is a really good resource. There is also a presentation on how Frostbite handles them.
Halfs work in exactly the same way as 32-bit floats but with less precision, so the interesting thing for us is how to convert from one to the other. Consider the number we computed above. The value of the unbiased exponent is 10 which once biased becomes 10 + 15 = 25, or 11001 in binary. For the mantissa, we could just truncate it or round it in some fashion. For this example we will round to nearest by adding a 1 in the 11th bit position which becomes 0011010011.
| 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
Unfortunately the half format does not have enough precision to represent any decimals from our number and 1234.5678 becomes 1235 (remember we rounded to nearest). When dealing with large quantities in shaders such as lighting values, it is often the case that numbers need to be brought into a range where decimals are representable.
Using them in shaders is relatively simple if all you want to do is pack data but do your operations in regular 32-bit floating point. GPUs have had packing and unpacking intrinsics for a long time, called f32tof16 and f16tof32, which pack these halfs into uints since they had no notion of a real half type. Let’s quickly look at the shader assembly for packing and unpacking two floats into halfs:
|
| ||||
|
|
RDNA is a complicated ISA and many instructions manipulate data with mixed precision such that the assembly can sometimes be unclear, but we can see the native full rate instruction v_cvt_f32_f16 exists to help us unpack data, and v_cvt_pkrtz_f16_f32 to pack it. This is the easiest way to convert to/from halfs in shaders that aren’t natively using half arithmetic. If the shader is natively using halfs (by using -enable-16bit-types), they can be uploaded and manipulated directly. Let’s see that in action:
|
| ||||
|
|
As you can see RDNA has instructions to deal with a native half type. Care must be taken not to mix precisions as it will produce slower code due to all the back and forth conversions. See the resources linked in the intro for a lot more detail, caveats and practical use.
RG11B10F
This is the first alternative floating point format that appeared specifically for lighting values in GPUs as part of DirectX 10. It was conceived as a standard 32-bit alternative to alleviate the bandwidth pressure of the fat 64-bit RGBA16F that the industry had been using for a while. Even though RGB10A2 had existed for a while on consoles, it didn’t exist on D3D9 and the format was uniform precision instead of floating point, thus RG11B10F was born.
The format has a few decisions baked in with regards to the type of data it’s meant to be used with. First and foremost, it doesn’t have a sign bit, meaning we can only store positive quantities in it. Second, the blue channel has one bit less than the other channels to fit in 32 bits, due to how our eyes perceive blue light less than red and green. The other interesting property worth mentioning here is that both the 11-bit and 10-bit floats here all have the same exponent range as the 16-bit half, meaning it is trivial to convert a half float into these smaller floats by just truncating the mantissa and shifting the sign bit out. For the opposite process, add the sign bit back in as 0 and pad the mantissa with 0s. Since the last number was already troublesome for half, let’s try encoding 12.34 instead. I’ll leave the whole derivation as an exercise and just put the results here.
half (12.34)
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
11-bit float (12.38)
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
10-bit float (12.25)
| 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 |
Let’s also add the packing and unpacking code here.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | uint PackFloat3ToRG11B10F(float3 value) { uint3 packed16 = f32tof16(value); uint ri = (packed16.r & 0x7ff0) << 17; uint gi = (packed16.g & 0x7ff0) << 6; uint bi = (packed16.b & 0x7fe0) >> 5; return ri | gi | bi; } float3 UnpackRG11B10FToFloat3(uint packed) { uint ri = (packed >> 17) & 0x7ff0; uint gi = (packed >> 6) & 0x7ff0; uint bi = (packed << 5) & 0x7fe0; return f16tof32(uint3(ri, gi, bi)); } |
Aside from this implementation you can find others here. Depending on your use case you might find variations useful.
RGB9E5F
One of the most mysterious formats around, RGB9E5 belongs to the family of shared exponent family of floats. If you’ve been doing graphics for a while you might remember RGBM which is a very similar concept, used before HDR render target and compression formats became popular (for example to compress lightmaps). In essence, 3 floating point numbers share the same exponent with different mantissa in order to make better use of precision. It is assumed that all 3 values are correlated somehow in magnitude, prioritizing the largest component. The format has gained traction with D3D12 adding optional support for rendering into it as a render target and a UAV. Some hardware still has to catch up but there’s a promising future ahead. Previously the format could be used to load in textures, the most prominent example of which was also to store lightmaps. The basic details of the format are well explained in the OpenGL extension specs and we can already glean some differences like no negatives and no NaN or infinity. There is however an even more interesting quote that outlines an important difference with regular floating point.
While conventional floating-point formats cleverly use an implied leading 1 for non-denorm, finite values, a shared exponent format cannot use an implied leading 1 because each component may have a different magnitude for its most-significant binary digit. The implied leading 1 assumes we have the flexibility to adjust the mantissa and exponent together to ensure an implied leading 1. That flexibility is not present when the exponent is shared. So the rgb9e5 format cannot assume an implied leading one. Instead, an implied leading zero is assumed (much like the conventional denorm case)
| Total Bits | Sign Bit | Exponent Bits | Mantissa Bits | Exponent Bias | Range | Smallest |
| 32 | No | 5 | 9 (x3) | 15 | ±65408 | 5.96046448e-8 |
The way to pack this format is to select the largest component, clamp the exponent to the allowed range with 5 bits for the exponent, then rescale the existing mantissa to account for that and pack them into the 32-bit uint that is to be our output. I have found many algorithms to do this, but the clearest so far is from this Microsoft repository. I added comments to the code and reworked it for clarity and understanding.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | uint PackFloat3ToRGB9E5F(float3 value) { // Clamp the channels to an expressible range const float MaxValue = asfloat(0x477f8000); // 0.ff x 2^+15 float3 clampedValue = clamp(value, 0.0f, MaxValue); // Compute maximum channel of clamped value float maxChannel = max(clampedValue.x, max(clampedValue.y, clampedValue.z)); // 'bias' has to have the biggest exponent plus 15 (and nothing in the mantissa). When added to the three channels, // it shifts the explicit '1' and the 8 most significant mantissa bits into the low 9 bits. IEEE rules of float // addition will round rather than truncate the discarded bits. Channels with smaller natural exponents will be // shifted further to the right (discarding more bits) // Reinterpret the maximum channel as a uint uint maxChannelUint = asuint(maxChannel); // Bias the exponent by 15, and shift the mantissa into the low 9 bits // 0x07804000 == 0b 0 00001111 00000000100000000000000 uint maxChannelBiased = maxChannelUint + 0x07804000; // Keep only the exponent of the resulting float // 0x7F800000 == 0b 0 11111111 00000000000000000000000 uint biasu = maxChannelBiased & 0x7F800000; // Shift the bias 4 positions to keep only 5 bits uint biass = biasu << 4; uint exponent = biass + 0x10000000; // Turn bias back into float and add to the original value to shift bits into the right places float bias = asfloat(biasu); float3 clampedBiased = clampedValue + bias; uint3 rgb = (uint3&)(clampedBiased); return exponent | rgb.z << 18 | rgb.y << 9 | (rgb.x & 0x1ff); } uint UnpackRGB9E5FToFloat3(uint packed) { float3 rgb = uint3(p, p >> 9, p >> 18) & uint3(0x1ff); return ldexp(rgb, (int)(p >> 27) - 24); } |
The Infinity, the NaN and the Denormal
While this isn’t strictly related to packing there’s quite a bit of demystifying to do regarding these “special” float values, and any packing or unpacking of data might want to take these into account, so here we go. First off, the only thing that defines these special floats is an exponent of either all 0s or all 1s.
Denormals
This is the special case when the exponent is all 0s. The only difference between them and a normal floating point number is that the implicit m0 we mentioned earlier is 0 instead of 1, and the exponent value is fixed at -126 (not -127). That allows us further precision and smaller numbers. In essence, a denormal floating point number looks like this:
{\Large (-1)^{\textcolor{30e6f0}{\textbf{s}}} · \textcolor{f58787}{0.m_1m_2m_3...m_{23}} \cdot 2^{\textcolor{3dff5a}{\textbf{-126}}}}
Some architectures don’t support denormals and treat them as if they were 0; this behavior is called flushing denormals to zero. Sometimes there are options to emulate them through software, which is slower.
Infinity
A floating value with the exponent set to all 1s and the mantissa set to all 0s is an infinity. This is what it looks like:
{\Large (-1)^{\textcolor{30e6f0}{\textbf{s}}} · \textcolor{f58787}{1.00000000000000000000000} \cdot 2^{\textcolor{3dff5a}{\textbf{128}}}}
Note there are +Infinity and -Infinity values depending on the sign bit. This value is returned when the float is not representable due to its absolute value being too large (> FLT_MAX in the case of 32-bit floats) or division by 0, etc. Arithmetic with Infinity tends to produce Infinity, for example the addition of 1.0f + Infinity = Infinity, the addition of Infinity + Infinity = Infinity.
NaN
A floating point value with the exponent set to all 1s and the mantissa set to anything other than 0 is a NaN. This is what they look like, these ugly not-numbers.
{\Large (-1)^{\textcolor{30e6f0}{\textbf{s}}} · \textcolor{f58787}{1.m_1m_2m_3...m_{23}} \cdot 2^{\textcolor{3dff5a}{\textbf{128}}}}
Operations that don’t have well-defined outcomes generally produce NaNs; these are the things you’d expect such as Infinity – Infinity, Infinity / Infinity, the square root of a negative number, etc. The awful thing about NaNs is that once you’ve got one in some matrix or vector they propagate throughout most operations you put them through, except perhaps things like min and max. To top it all some graphics cards treat NaNs differently and they are a source of hard to track bugs. Imagine reading one from a texture, doing lighting calculations, then blurring the screen (bloom or depth of field) and smearing your screen with them; peak debugging experience. Apparently neural network training also suffer these quite a bit. Because NaNs don’t have a single representation they are classified sometimes as QNAN (quiet) and SNAN (signalling), and they have complicated meanings we don’t care about.
Packing World Positions
 One common application of floating point is world positions (note that packing e.g. vertex positions is possible with the techniques we’ve seen already). We can use 3 floats to represent coordinates in 3D space. This works reasonably well for small worlds but breaks apart as they become larger. It turns out that the versatility offered by floating point can be detrimental in treating all areas of our virtual world equally. Visualizing the non-uniform precision of floating point can help us answer why this happens. In an intuitive sense, the more bits we devote to kilometers, the less we can devote to centimeters. Let’s assume a value of 1.0f == 1 meter and look at this table, showing distance from the origin and the maximum precision at that distance:
One common application of floating point is world positions (note that packing e.g. vertex positions is possible with the techniques we’ve seen already). We can use 3 floats to represent coordinates in 3D space. This works reasonably well for small worlds but breaks apart as they become larger. It turns out that the versatility offered by floating point can be detrimental in treating all areas of our virtual world equally. Visualizing the non-uniform precision of floating point can help us answer why this happens. In an intuitive sense, the more bits we devote to kilometers, the less we can devote to centimeters. Let’s assume a value of 1.0f == 1 meter and look at this table, showing distance from the origin and the maximum precision at that distance:
| Units | Precision |
| 1 | 0.0000001 |
| 16 | 0.000001 |
| 64 | 0.00001 |
| 1024 | 0.0001 |
| 8192 | 0.001 |
Precision starts off good, in the order of micrometers. However, since precision decays exponentially, by the time we get to 8km it has reached a point where we can only resolve increments of 1mm; at 65km it can only resolve differences of 1cm. This is the theoretical case; successive operations on positions such as matrix multiplication rapidly accumulate floating point error and in practice it completely breaks apart much earlier than that. The solutions below revolve mainly around preserving high precision at a large scale and resolving these positions into a local space centered around the camera for physics or rendering. This allows us to keep our existing code, which is fast and GPU friendly. Below are a few techniques I know of; I’ll list some advantages and disadvantages although I haven’t tried them all.
Double
 Using double precision is an option if your worlds are extremely large and you can live with the performance and memory impact. Precision still degrades eventually much later, at a distance of 4,398,046,511,104 (~4 billion km). Common problems with this solution are performance and memory; objects in the world will need twice the data to store their transforms, with the consequent increase in bandwidth and cache. Math operations are generally half rate compared to float. You can perhaps create specialized matrices that mix float for rotation and scale and doubles for positions for a compromise, and be careful which positions and matrices are in world space and local space. The conversions between double and float can add cost. Star Citizen is famously known for having gone done this route.
Using double precision is an option if your worlds are extremely large and you can live with the performance and memory impact. Precision still degrades eventually much later, at a distance of 4,398,046,511,104 (~4 billion km). Common problems with this solution are performance and memory; objects in the world will need twice the data to store their transforms, with the consequent increase in bandwidth and cache. Math operations are generally half rate compared to float. You can perhaps create specialized matrices that mix float for rotation and scale and doubles for positions for a compromise, and be careful which positions and matrices are in world space and local space. The conversions between double and float can add cost. Star Citizen is famously known for having gone done this route.
World Regions
In this scheme the world is divided into regions and objects have positions relative to the region’s origin. The size of each region in meters defines the maximum floating point degradation you can get. Starting chunk coordinates from the center can give an extra bit of precision (i.e. object coordinates from -500 to 500 instead of 0 to 1000). Large games like flight simulators can make use of such a scheme and the precision is greatly increased. The most straightforward approach is to store the region explicitly using a few extra bits. For example, we can store these regions in a 32-bit integer by devoting 12 bits for the horizontal plane and 8 bits for chunks on the vertical plane, as the range for the sky on Earth is shorter. An alternative to keeping the region explicitly stored per object is to have that object belong to that region and reconstructs the coordinate later, passing it along to avoid storing the memory, so the region coordinate is effectively shared between all the objects at the cost of maintaining a region structure (likely some sort of hashmap).
Snapping Origin
This is a simpler method that involves keeping your floating point coordinates but resetting to the  origin every other N units. For example, every 1000 meters, all objects in the world are snapped back relative to the origin, keeping the coordinates in a sort of local world space. This has the computational cost of having to translate objects periodically at the boundary and also means your objects cannot really be loaded or live beyond a certain distance from the camera, but it can maybe work for smaller procedural worlds. This was used on older games but a few Unity games apparently use this technique because Unity itself doesn’t have much support for it.
origin every other N units. For example, every 1000 meters, all objects in the world are snapped back relative to the origin, keeping the coordinates in a sort of local world space. This has the computational cost of having to translate objects periodically at the boundary and also means your objects cannot really be loaded or live beyond a certain distance from the camera, but it can maybe work for smaller procedural worlds. This was used on older games but a few Unity games apparently use this technique because Unity itself doesn’t have much support for it.
Fixed Point
Games don’t normally need precision in the order of micrometers, which you get at positions around the origin. An alternative is to fix the precision to a certain desired sub-meter precision and devote the rest to meters. Just as an example let’s say we wanted 12 bits (1/2^12 for a quarter mm) of decimal precision, that still leaves us with 2^20 or ~1000km to play around with. It comes with all the caveats of fixed point math (e.g. easy to overflow) and if you need vastly different scales such as in a space game it might not be enough, but it takes the same amount of memory as float. Another downside is you need to develop a math library that operates on fixed-point math, which is likely less performant. You might already be using it for deterministic positions so it could be an option. The only game I know of using fixed math is StarCraft 2. Another option is to simply use integers as millimeters, it’s similar but instead of having an explicit binary point it’s implicit in decimal.
There are more techniques that games use such as Godot and the technique used for the game Ixion, which is to bring faraway objects closer while scaling them down to compensate.
Packing Normals
Normal packing comes up often in graphics, so much that specific methods have been devised to pack them as efficiently as possible with the highest quality. Normals are a subset of vectors where the main assumption is that we want to encode a direction, i.e. the quantity we are interested in are points on the unit sphere. The topic has been researched quite extensively and it’s hard to delve into every possible algorithm that has been developed, so instead I’ll describe existing literature, sources, and popular approaches.
GBuffer Normals
Packing normals in the GBuffer has been a source of interest since deferred rendering became popular during Generation 7. The majority of developers moved to this method for opaque surfaces and the industry today has few examples of forward engines. Storing a normal using floats is normally out of the question due to bandwidth, but packing them as 8-bit normalized quantities in the straightforward way we’ve described so far cannot provide enough quality for specular BSDFs or cubemaps; the quantization artifacts are too great. The next obvious approach, storing X and Y and reconstructing Z, shows a lot of artifacting too.


Aras Pranckevičius wrote down this well known comprehensive analysis of techniques and instruction counts for older microcode, Compact Normal Storage for Small G-Buffers (2009). It was one of the earliest attempts I’m aware of at measuring error and ALU cost between techniques. At the time many games were storing normals in view space, so many techniques tried to exploit it. Crytek threw its hat in the ring several times, and Best Fit Normals (2010) was one of the most original techniques out there: it essentially uses a cubemap (although practical implementations used a 2D texture) to encode an optimal fit for a given normal. To my knowledge it hasn’t been used outside of CryEngine games like Ryse, there’s an interesting writeup here. Octahedral Normal Encoding (2010) became a very popular technique due to its relative simplicity and high quality; to my knowledge it was popularized through this comparison. Crytek again provided a compelling alternative in The Art and Technology behind Crysis 3 (2013), providing a stereographic projection approach with good quality and ALU. The paper Survey of Efficient Representations for Independent Unit Vectors (2014) attempted to formally compare a large set of compression techniques by analyzing them in great detail, and is well worth a read. Notes on GBuffer Normal Encodings (2015) explores lesser known techniques. Shortly after that, Signed Octahedral Normal Encoding (2017) appeared as a minor variation of the original.
With all that, let’s quickly go over a few of the popular options; I have only considered a couple of popular options that target world space normals, of which there aren’t that many. In my experience, aside from being inconvenient to work with, view space normals tend to suffer from jittering artifacts since the values change every frame, whereas world normals are stable under movement even if quantization looks bad. I made a simple Shadertoy for visual comparison, and a bit of C++ code to compute the actual error values by iterating through all points on the sphere. All options are packed in 24 bits. For implementation ease I used my own HLSL++ library. I have computed the error metric as a difference between the two points on the sphere instead of an angular metric as the precision of acos() created many artifacts in vectors with very small differences. It should be close anyway for a unit sphere. Íñigo Quílez made a much more comprehensive comparison.
Trivial Encoding

|
| ||||
|
|
This is the baseline. It’s the cheapest, but its quality at 24 bits is inadequate to properly represent normals. Its average error is an order of magnitude worse than any of the options below. The main reason for this is that this encoding is able to represent a lot of redundant data, directions that are essentially the same after normalization but still require bits to represent.
CryEngine 3 Stereographic

|
| ||||
|
|

The stereographic encoding is a classic derived from the Stereographic Projection used for maps. It looks promising in terms of cost and error metrics, but (and the image already hints at it) we can see how the error distribution clearly favors one direction over another. At 24 bits this might be acceptable but lowering the bitrate will cause some normals to degrade much faster than others. This type of characteristic was exploited for view space normals, but Crytek seems to have been able to use that for world space normals.
Octahedral
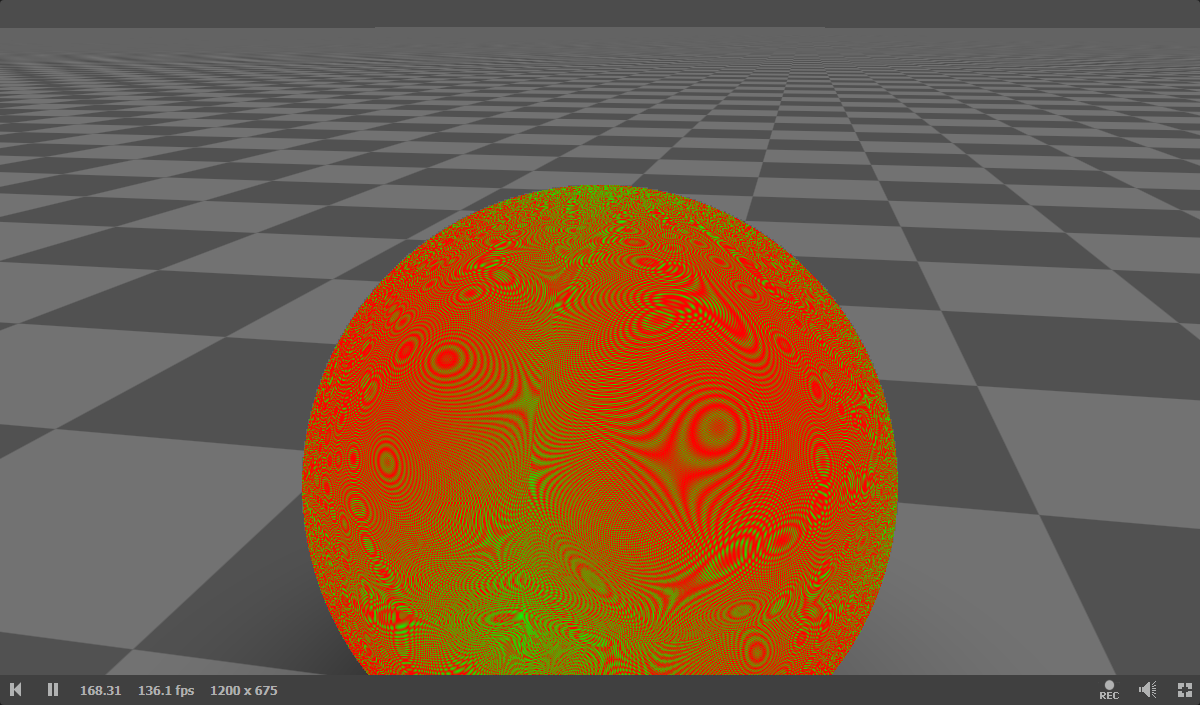
|
| ||||
|
|
Octahedral is the most popular way of encoding to encode world space normals in the graphics world as far as I’m aware. The error distribution is more uniform so it can be used with lower bitrates and the ALU cost is competitive. Conceptually, we are trying to map the set of normals to the octants of an octahedron. This octahedron is mapped to the 2D plane and reconstructing the normal is a matter of knowing which octant the normal lies in.

Since we devote all bits to the points on the surface of the octahedron, we cannot really represent any vector inside or outside of it, which means all our bits are devoted to unique directions. The error distribution around the octants is apparent by looking at the image.
Epilogue
We clearly touched on a lot of topics here but I wanted to give a holistic and ordered approach to all the different ways I know of to pack data; from cramming colors into as few bits as possible, representing data in the arcane floating formats and encoding normals via octahedral magic, these techniques save memory and bandwidth to make your processor happy. Hopefully you can apply these building blocks to the many different domains within programming where it makes sense and have fun optimizing your data. I would like to thank @vassilis3d, @moguzhan_k and @aortizelguero for helping me out with readthroughs, feedback and good humor.
The best fit normals approach is used in Godot! (https://github.com/godotengine/godot/pull/86316) We ended up choosing it over octahedral encoding for our G-buffer normals because we wanted to have cheap decoding and we wanted to be able to easily visualize the G-buffer normals without having to decode them.
I had no idea that was the case! It’s true that you see a sort of speckled normals buffer. How does this technique compare in terms of error metrics? The 2014 comparison paper puts it in an unfavorable light but I haven’t been able to compare. The fact that it needs a texture means it was a bit difficult for me to test on the CPU
Hello, great post 🙂
I’m wondering in the following function:
uint bfe_u32(uint value, uint offset, uint bits)
{
uint mask = (1U <> offset;
return shiftValue & bits;
}
shouldn’t the return line be:
return shiftValue & mask;
instead of
return shiftValue & bits;
Hey Marko, thank you! And you are absolutely right about bfe, it should have been masked with mask, not sure what happened there. Thanks for letting me know 🙂
Thanks for the great blogpost, it is very helpful!
One question: inside the first version of PackFloat4ToRGBA8Snorm(), don’t we need to mask out our bits? When dealing with signed integers negative numbers would contain ‘1’s outside of the 8 bit we need due to two’s complement, which we should mask out.
Hi Alexander,
Thank you for the great comment and correction. It was indeed wrong and the bytecode was incorrect too. I have now amended and tested it works correctly. I’m very glad you enjoyed it and clearly read very thoroughly!
That’s a great article! So comprehensive. You could have split it into multiple articles and have content to post on your blog for months 😉
I’ve spotted a small bug: Function
bfi_b32doesn’t use its parameterbase.Also, please note that AMD assembly instruction
v_readfirstlane_b32is not a simple MOV to a scalar register. It is one of the “wave” instructions that replicates the value from a first active thread to all threads within a wave. It could have been used in your example due to the way your particular shader was written overall – what value you used as an input. In a general case, if the value is not uniform (scalar) across threads in the wave, it wouldn’t work correctly.Dzieki Adam! I realize it’s long but I don’t know why I like it that way 🙂 I can give it more cohesion than multiple.
Thanks for the correction, I renamed base to value and forgot to update the parameter.
I see what you mean, I rewrote the surrounding shader to make sure it all happens in vector registers, it’s simpler to reason about, at least for the purposes of the article. Compiler output is finicky!
Pingback: GPU utilisation and performance improvements – Interplay of Light
I found this blog here, because I was looking for nice ways to pack my data into bitfields in Nabla; I thought I should add a few points worth mentioning
– DONT SHARE bitfield structs between CPU and GPU: DXC supports bitfields yes, while it would work “theoretically” C++’s implementation of bitfields are implementation-defined and can vary based on compiler: https://mocelik.com/c/bit-fields/
– Even if we had some consistently defined bitfields across different compilers, there is still these DXC issues: https://github.com/microsoft/DirectXShaderCompiler/issues/8470
https://github.com/microsoft/DirectXShaderCompiler/issues/5554
one of these issues have been open since 2023!
– So what’s the solution we went with? (We use DXC to compile HLSL202x to SPIRV)
We used DXC’s spirv_intrinsics: https://github.com/Devsh-Graphics-Programming/Nabla/blob/68ed2fa4ed692782af6d45e8a888a7f35099371e/include/nbl/builtin/hlsl/spirv_intrinsics/core.hlsl#L310
For CPU and GPU compatability in our headers we use another function on top which uses spirv intrinsics on GPU but also have a CPU impl when being compiled with C++.
Now the IHV compiler can successfully use it’s own instructions when compiling the SPIR-V! which would get you those
bfeorbfiAMD instructions